Magento & RDS Aurora - High CPU Usage issue
11 Dec 2016
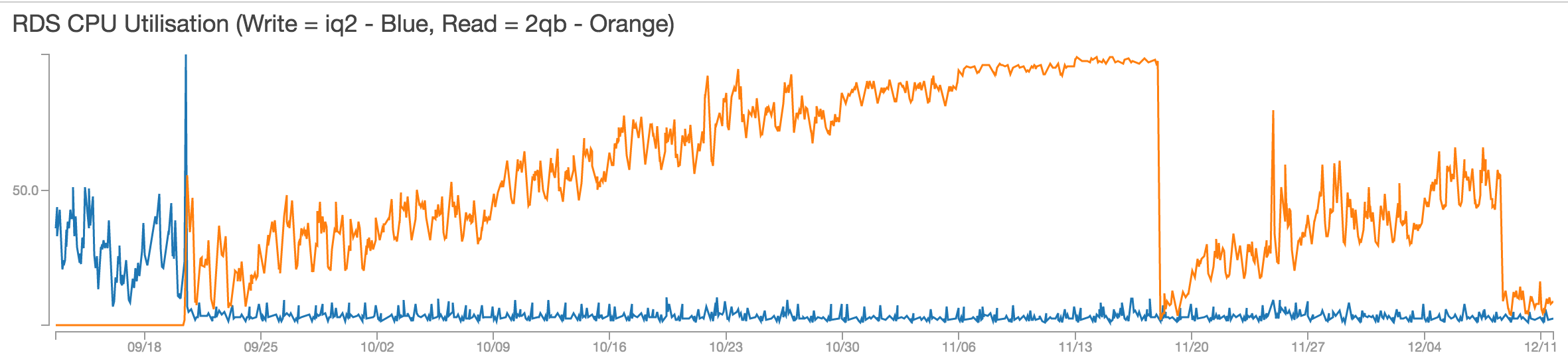
After fixing the split & write issue with split database in previous post on RDS Aurora with Magento, I’ve been monitoring the performance closely on CloudWatch. A new issue then has arised as the graph shows below.
The Not-So-Fun Facts
- The orange line is the CPU utilisation of read endpoint while the blue line is of the write endpoint
- When the orange line first starts to go up is the time when we splitted read and write endpoints
- As the graph shows, the CPU usage keeps increasing consistently during week after week. It increases approximately 10% every week.
- NewRelic reveals no major problem with normal transactions (besides general Magento MySQL hogging)
- The performance did not seem to degrade even at 99% RDS CPU utilisation average
- The first drop on the graph around 18/11 is RDS being through a maintenance and having the service restarted
- After the maintenance, the graph again shows the same trend of CPU usage being increased gradually in the same manner it was before the maintenance.
- The second drop on 10/12 is the result of my finding detailed below.
The Struggles
- Obviously there is no root access to the RDS instance to see what’s hogging the CPU, at various points of failing to identify the cause, I’ve thought that it’s the RDS instance’s fault and hoped that maintenance will correct it.
- Could slow query be the issue? Yes it could be. However, I’ve been hold back by the question of if it’s the slow query issue problem, unlikely a service restart will be able to fix it - as without database or infrastructure changes, the same query with the same (or larger) dataset will occurs again.
The Epiphany
- I turned my attention to Magento log randomly on one day. Well and behold, I found something interesting
$ php shell/log.php status
-----------------------------------+------------+------------+------------+
Table Name | Rows | Data Size | Index Size |
-----------------------------------+------------+------------+------------+
log_customer | 144.58K | 8.93Mb | 5.55Mb |
log_visitor | 221.69K | 36.75Mb | 0 b |
log_visitor_info | 209.23K | 119.62Mb | 0 b |
log_url | 13.18M | 997.13Mb | 817.89Mb |
log_url_info | 57.50M | 10.61Gb | 0 b |
log_quote | 33.10K | 3.69Mb | 0 b |
report_viewed_product_index | 18.90M | 928.97Mb | 2.71Gb |
report_compared_product_index | 12 | 16.38Kb | 81.92Kb |
report_event | 21.90M | 1.08Gb | 2.36Gb |
catalog_compare_item | 11 | 16.38Kb | 81.92Kb |
-----------------------------------+------------+------------+------------+
Total | 112.09M | 13.79Gb | 5.90Gb |
-----------------------------------+------------+------------+------------+
- Those are homougous tables that supposed to have a cleaning done every weekend to maintain only 30 days of visitor data.
- The job for cleaning out the log is
$ php shell/log.php --clean --days 30 - However, running said command resulted in a hang process. Digging further into the core code of that job shows that there
are a few logic involves large tables (
log_visitor,report_event,report_viewed_product_index). At this stage, my assumption is the number of row is too large for the job to be performed successfully with the configured memory assigned for an individual PHP-FPM process. - As the result of failing clean up, my second assumption is that MySQL tries to cache or process the index of the log table gradually hence having its CPU increased in such manner. *
- A few things to be considered
- The frontend session lifetime is only 5 days
- BA is using data captured by Google Analytics rather than those from the log tables
- So having those logs there are not much useful, the only table that are being utilised is
report_viewed_product_index; which is for the recently viewed product block
The Solutions
- As the Magento script (preferred method)failed to clean out the table log, manual truncate is an alternative approach. Proceed with caution and always backup your database. Be extra cautious if the Magento site has recently view products block.
- Obviously there needs to be a better script that can handles the log cleaning. I’m currently in the process of building this and investigate where is the exact breaking point of Magento core job.
- I also looked into disable to log event (https://gist.github.com/jedgalbraith/3362521) as this will be a neater solution given not much data is being utilised. However, as recently viewed product block still relies on a couple of tables, this approach needs to be thoroughly tested before bringing it to production.
* I could be mistaken the real underlying issue here since amittedly deep MySQL knowledge is not my strong suit so please let me know via email if I misread and wrongly analysed the situation.